API开放平台场景示例:获取所有部门
时间:2024-11-01 11:54:36 作者:喜米网络 来源:阿里云调用“根据部门ID获取部门的基本信息”接口,从返回值中获取根部门ID,传入“获取指定部门ID下的子部门”接口,递归获取部门分页数据。
相关接口
基本流程
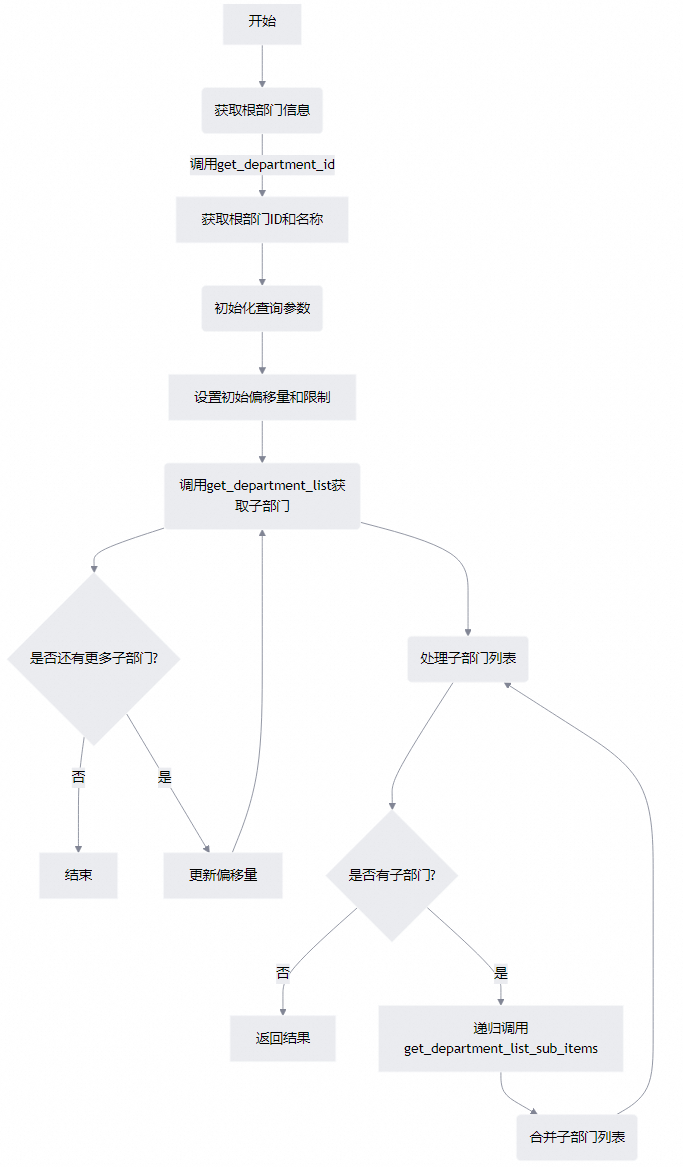
Python示例代码
# -*- coding: utf-8 -*-import requests# 导入获取访问令牌的函数,路径根据实际情况进行修改,或直接给access_token赋值用于测试from api_demo.get_access_token import access_tokendef get_department_id(v_depart_id): """
根据部门id获取部门的基本信息
https://mailhelp.aliyun.com/openapi/index.html#/operations/alimailpb_ud_DepartmentService_GetDepartment
:param v_depart_id: 部门ID,用于获取特定部门的信息
:return 返回包含部门信息的JSON响应
"""
url = f"https://alimail-cn.aliyuncs.com/v2/departments/{v_depart_id}"
querystring = {}
headers = { "Content-Type": "application/json", "Authorization": "Bearer " + access_token
}
response = requests.request("GET", url, headers=headers, params=querystring) print('##########################################################################') print('请求参数:', querystring) print('返回参数:', response.status_code, response.text) print('##########################################################################') return response.json()def get_department_list(offset, limit, v_depart_id): """
获取指定部门 id 下的子部门
https://mailhelp.aliyun.com/openapi/index.html#/operations/alimailpb_ud_DepartmentService_ListSubDepartments
:param offset: 分页查询的起始位置
:param limit: 每页查询的数量
:param v_depart_id: 部门ID,用于获取该部门下的子部门
:return: 返回包含子部门列表和总子部门数量的列表
"""
url = "https://alimail-cn.aliyuncs.com/v2/departments/" + v_depart_id + "/departments"
querystring = {"offset": offset, "limit": limit}
headers = { "Content-Type": "application/json", "Authorization": "Bearer " + access_token
}
response = requests.request("GET", url, headers=headers, params=querystring)
v_departments = response.json()
departments_items = v_departments["departments"]
v_total_sub = v_departments["total"] return departments_items, v_total_subdef get_department_list_sub_items(department_id): """
递归调用获取指定部门 id 下的子部门
:param department_id: 部门ID,用于查询该部门下的所有子部门
:return: 返回一个包含所有子部门的列表
"""
# 初始化分页查询的起始位置和每页数量
offset = 0
limit = 100
# 初始化用于存储所有子部门的列表
total_departments_items = [] # 打印开始查询的部门ID
print('##########################################################################') print(f'开始查询:{department_id}') while True: # 调用get_department_list函数获取当前页的子部门列表和总子部门数量
departments_items, v_total_sub = get_department_list(str(offset), str(limit), department_id) # 打印当前页码、子部门列表和数量
print(f'子部门:第{(offset // limit) + 1}页:{departments_items}') # 将当前页的子部门列表添加到总列表中
total_departments_items.extend(departments_items) # 如果已获取的子部门数量达到或超过总数量,则结束循环
if len(total_departments_items) >= v_total_sub: break
# 更新分页查询的起始位置
offset += limit print(f'合计:{v_total_sub}个子部门') # 递归获取子部门的子部门
for item in total_departments_items: # 递归调用自身获取每个子部门下的所有子部门
sub_items = get_department_list_sub_items(item['id']) # 将子部门的子部门添加到总列表中
total_departments_items.extend(sub_items) # 返回包含所有子部门的列表
return total_departments_items# 获取主部门IDroot_department = get_department_id('$root')
root_department_id = root_department['id']
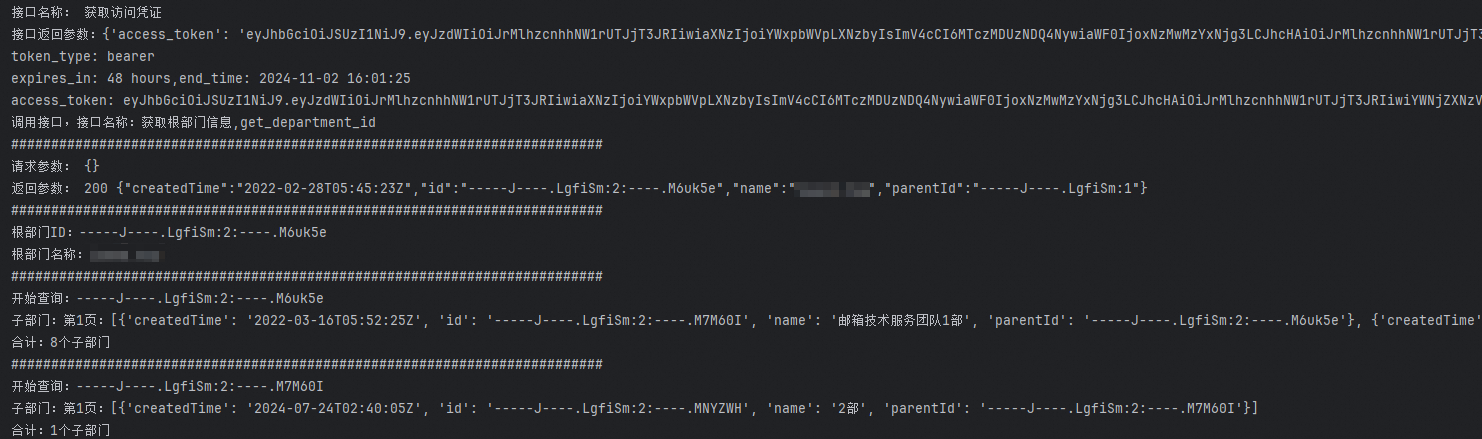
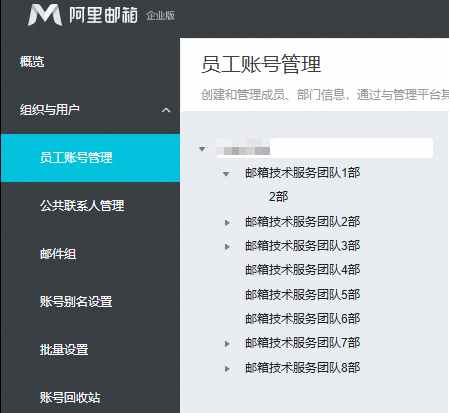
root_department_name = root_department['name']print(f'根部门ID:{root_department_id}')print(f'根部门名称:{root_department_name}')# 获取所有子部门total_departments = get_department_list_sub_items(root_department_id)print(total_departments)运行结果


上一篇:快速入门
